After becoming enamored with the pair of cheap phone lens attachments I bought, I decided to try out the common “60x” microscope. Although it doesn’t use the same magnetic ring attachments and is supposed to go with iPhones (it uses a form-fitting case to attach), I saw a review where someone mentioned gluing the ring magnet from another lens onto it to make it work with other phones. So I ordered one to give that a try.
A bit of superglue and a spare ring magnet makes it quite usable on my HTC One XL. Here are the same pixels from my television, shot with the microscope and with the macro lens. The fine structure of individual pixels resolves a little better with the microscope.
Here is an ink and paper drawing (a closeup of this) illuminated with the LEDs that come with it.
The main downside with this lens is that the visible area makes up only a small portion of the sensor. The shots above are “zoomed”; the visible area is actually about 1/3 the width of an uncropped image. Still, the design of the barrel along with the built-in lights makes it easier to get a good, well-lit image than it is with the macro (which creates disruptive shadows over the subject in most lighting). So, $5.23 well-spent.
Fisheye lens with magnetic ring attachment. Teh awsum.
Phone lens attachments are my new favorite thing. I got a pair of them (this fisheye and this macro/wide-angle) for around $11, and they are delightful. You put a little stick-on metal ring on your phone’s camera, and the lenses attach magnetically. In the first shot from the gallery you can see the field of view for the macro, the un-augmented camera, then the wide-angle and fish-eye.
Enough chatter. See some highlights of the fisheye and macro from my first few days with them (using my HTC One XL).
That’s a question that’s been tough for me, as it is for a lot of amateurs with decent cameras who occasionally get the chance to make a bit of money through their photography. So just to provide some points of reference, I’ll share a few of my experiences.
This is the first photo I made money from:
Education, a stained glass window at Yale created by Louis Comfort Tiffany
An editor from New Scientist contacted me through Wikipedia. (I had actually released it public domain, but they wanted to license it directly.) I had no idea what to ask, which I think I told them, and I think the $300 I got for it was their first offer to me. (Actually, when the wire transfer came through, it was only $275, minus an additional $10 bank fee.) It was used as a half-page illustration in the middle of the 19 July 2008 issue. Given that this was their first offer, it was probably toward the low end of what I could have gotten.
In 2009, made $100 from another public domain photo, of a painting of the Great Fire of London. Parthenon Entertainment contacted me through Wikimedia Commons, and I explained that, in the US, my photo wasn’t even eligible for copyright, but that I would license whatever rights I might or might not have in the photo for $250. They said limited budget was why they turned to Commons in the first place, and they could just offer $100. I said yes and counted myself lucky.
Also in 2009, I got $50 for a shot of a Loring peach from Macore, a company that makes plant tags and labels for nurseries. They would have used the CC license if I was okay with with a website only credit, but they didn’t want to put a credit on the actual plant tag they made with it.
“Austin Joseph”, perhaps
In 2010, I discovered using TinEye that an digital textbook company was using an image I took of a sign-holding protester from a health care reform town hall meeting for one of their videos, without following the license. I sent them an email asking them to release video under the appropriate license… or alternatively, I’d take $400 for permission to use the image. They took that option. Unfortunately, I don’t know who the young man in the photo is (and of course, have no model release form, although that shouldn’t be necessary for the types of editorial use in an educational context that they are using it for). An anonymous editor tagged it on Commons as “Austin Joseph”, but that’s not much help.
Later in 2010, the journal Science published a portrait I made of historian Steven Shapin in a review of his book, crediting the image as “SAGE ROSS / WIKIMEDIA COMMONS” but without mention of the license. Since they really ought to know better (and they are pay-walled, and subscriptions are very pricy), I explained in an email to the editors how they had neglected to use a free license and attached an unsolicited invoice for $2000. I never heard back.
In early 2012, after I sent an email to the Pittsburgh Zoo about some photos of their beautiful infant gorilla, they put many of them up on their blog, and then the photos spread to ZooBorns. Then, I got contacted by TODAY.com; I ended up asking for and getting $200 for the use of four shots on their (then new) Animal Tracks blog. (Tragically, the baby gorilla died a few months later.)
In March 2012, I got a cold email from Envision Communications, a political ad firm that had seen a Tea Party protest photo of mine on a random blog. (Incidentally, the blog credited me by name, but didn’t follow the license.) They wanted to use it in a campaign commercial they were producing (for a Democrat). I figured it was time to aim higher with my pricing (and hey, TV!) so I think I threw out $1000. They said their budget would allow more like $150, and I ultimately got $175 for it (for use in only one commercial). The producer said he’d let me know once it aired so I could see it, but that must have fallen off his radar during the hectic campaign season. (UPDATE: I pinged them, and it turns out the spot didn’t end up running.)
UPDATE – 2014-06-07
I got contacted earlier this year by Cengage Learning, who requested to use three of my photos from tea party and health care protests for a journalism textbook. They asked for an invoice in the first email, so I said I would send one shortly for $1800. They said the maximum budget was $350 per photo, and corrected that to $300 shortly after. It took a few months, but I finally did get $900 for the three of them.
One trend I noticed is that I’ve gotten a lot of photo inquiries to my (now out-of-date) work email, even though it’s not the account associated with my photos on either Flickr or Commons. The takeaway, I think, is that people will use whatever email they find when they google your name or look at your profile, so if you want people to randomly offer to pay you for photos, it’s good to add your human-readable email address somewhere easy to find.
UPDATE – 2014-09-12
Since the previous update, I’ve licensed another photo, of my grandpa’s old hinny, for use in the 2nd edition of Carl Zimmer’s book Evolution. I asked for $300, and the photo editor said her per picture limit was $150. I wanted to test the supposed limit, so I said I could do $200; that apparently needed to be run by the publisher, but I ultimately got $175 (after a few weeks). Probably it wouldn’t be worth the risk for just the extra $25, but it was good to get that data point; in cases where I think it could fetch considerably more than the stated limit, I’ll definitely hold out in the future.
I’m taking the free Stanford Human-Computer Interaction course, and I thought I’d post the storyboards from the second assignment. We started with “point of view” that expresses a problem and an approach to solving it, then on to storyboards and design mockups. Mine:
In order to change the way we buy and consume things, user-generated reviews — and the systems for creating and using them — need to be free-as-in-freedom, controlled by the communities that make and use them (not by big corporations for their own ends).
My first storyboard: a free culture review site, from the perspective of someone like meThe second storyboard: A little bit of a broader perspective, on how I imagine a free culture review site could help small businesses
You can also see my mockups for two different user interfaces for this idea:
Yesterday I went to an open discussion about SOPA with Jason Altmire, who represents my district. He came out against SOPA at the end of the event. But one thing that bugged me was that just about everyone used “theft” as a synonym for copyright infringement. And this “theft” by rogue websites in China and southeast Asia, everyone supposedly agrees, is a serious problem, even if SOPA isn’t the right answer.
Consider a typical case where somebody downloads a Hollywood movie to watch, without paying for it. Taking this movie wasn’t authorized by the copyright holders. But the copyright holders still own it. They still have all their copies, and they are still free to make more. They can distribute and license it as they wish. They can make sequels and spin-offs and t-shirts and bobble-heads.
What would you call that? I would call it copyright infringement, but I wouldn’t call it theft.
Now imagine a different scenario. A work you have is taken from you. And once it’s been taken, you can no longer make copies. In fact, you have to get rid of all the copies you have. When it was yours, you could make copies, send them to your friends, make derivatives, use it as a jumping off point for new works. You could do with it as you pleased. Now, you can’t do any of that without the permission of the person who took it from you.
Would you call that theft?
I would call it Golan v. Holder. Wikimedians are having to get rid of thousands of public domain works from Wikipedia and Wikimedia Commons that used to be public domain in the U.S.—used to belong to the public, to use and copy and build from—which were put back into copyright by Congress. And the Supreme Court just decided that in fact, that’s just fine.
Blog more, especially about kid-oriented media and culture. There’s a big lack of free culture when it comes to kids stories and media. I want to try to catalyze some kind of free culture project for an audience of kids.
Do better in the Stanford Human-Computer Interaction class than I did in Introduction to Databases last year. (I learned a lot, but didn’t end up finishing because the final was scheduled for right when Everly was born, so I didn’t take it.) These Stanford online classes are awesome.
Get involved with local politics. Somebody’s got to do it.
Make a functional web app. I’m going to try to learn Python and Django web development by trying to build an open reviews site, where anyone can review anything. In 2012, I want to at least build a very basic site, whether or not it goes somewhere.
Looking for a cool gift idea for the geek who has everything (or the anti-consumerist geek, or the free culture geek)? I just claimed slot #3 (out of 20) in the WTactics “become a character” program. That means someone special to me will be having a freely-licensed portrait made of her as a fantasy mermaid priestess. The portrait will also become a card in the community-developed open source collectible card game WTactics, which is a spin-off of the successful (and fun!) free computer game Battle for Wesnoth.
We picked up some Toy Story toys at a garage sale this weekend, which have become the center of Brighton’s life for the time being.
John Lasseter, director of Toy Story, has a great story about how, five days after the movie came out and audiences started falling in love with it, he
realized that Woody, Buzz Lightyear, all the Toy Story characters… they didn’t belong to us at Pixar anymore,
but to the people who had made those characters a part of their own lives.
Of course, the lawyers at Pixar will tell you a very different story.
Last week was the beginning of something that might end up pretty huge in the world of free culture, copyright and open access activism. Aaron Swartz, a free knowledge activist hacker with ties to the Wikipedia community, was indicted by the federal government for allegedly downloading millions of files from JSTOR (an academic journal database) with the intent to distribute them on P2P networks. The actual charges aren’t for copyright infringement or anything directly related, however. They are for wire fraud, computer fraud and related offenses based on the way he allegedly obtained the files, by connecting to the MIT computer network and setting up scripts that downloaded files and dodged attempts to cut off access. (SJ Klein has a great overview of the charges and context.) Aaron never released this trove of files, and has reportedly turned them over to JSTOR.
He may have been planning to, however. You can get some insight into his thinking from the Guerilla Open Access Manifesto, which essentially advocates widespread and systematic sharing of restricted scholarship.
(The original is offline, but an apparently complete version that may or may not be authentic showed up on pastebin recently.)
In response to Swartz’s arrest, Wikimedian and free software developer Greg Maxwell actually did release a trove of JSTOR files: the complete archive of Philosophical Transactions of the Royal Society (the longest-running scientific journal, started in 1665) through 1922. These have all entered the public domain in the legal sense, but not the practical sense. You can only get them under restrictive terms and/or for high prices (either through JSTOR or from the Royal Society).
You should read Greg’s whole essay. Here’s the conclusion:
If I can remove even one dollar of ill-gained income from a poisonous industry which acts to suppress scientific and historic understanding, then whatever personal cost I suffer will be justified — it will be one less dollar spent in the war against knowledge. One less dollar spent lobbying for laws that make downloading too many scientific papers a crime.
I had considered releasing this collection anonymously, but others pointed out that the obviously overzealous prosecutors of Aaron Swartz would probably accuse him of it and add it to their growing list of ridiculous charges. This didn’t sit well with my conscience, and I generally believe that anything worth doing is worth attaching your name to.
A lot of free culture and open access advocates draw a line between Aaron and Greg. Greg is praised for taking his stand, but few are endorsing Aaron’s alleged actions, only condemning the gross disparity between the charges and the alleged actions — while ignoring or opposing the argument of the Guerilla Open Access Manifesto. (That line between them is copyright law.)
Me, I’m not so sure. I’m not sure copyright law has enough moral force to be a meaningful distinction. I’m certainly not convinced terms of use have enough moral force to matter here. The bottom line is, the world of academic publishing and distribution is changing… but painfully slowly. Academic publishing isn’t cheap, professional-grade digitization of old journals isn’t cheap, and there’s no single fix for keeping everything people like about academic publishing and archiving (like peer review and professional editing and easily searchable databases) while getting rid of what we don’t like (like paywalls), without totally upending the industry. Greg-ites — who liberate public domain material — and Aaron-ites — who want to liberate all scholarship, copyright be damned — both have the same practical consequences: to push paywalls and organizations that rely on them closer to irrelevance, and to place the burden of organizing and indexing and providing access onto open knowledge communities and organizations (and big data companies like Google).
Bob Kraut, Rosta Farzan, and Piotr Koniecnzy working the Wikipedia booth
I spent the last several days in D.C. at the annual convention of the Association for Psychological Science (APS), along with Wikipedian Piotrus and Wikipedia researchers Rosta Farzan and Bob Kraut, talking to psychology researchers about Wikipedia. We probably talked with 200 people, and almost everyone we talked with was supportive of–if not downright enthusiastic about–trying to improve Wikipedia’s psychology coverage.
Several months ago, with the vocal support of APS President Mahzarin Banaji, the APS launched their “Wikipedia Initiative” to get psychologists into editing Wikipedia. So far, the main thrust has been their APS-WI portal, which aims to give newcomers a clear way into Wikipedia and point them toward articles in their area of interest that need work–and at the same time, systematically test different approaches to getting people involved.
Before the convention, the APS Wikipedia Initiative had recruited 263 psychologists. 68 of them had started editing, with over 400 different articles edited among them. (Now 13 more have signed up, and 10 more have started editing.)
I had the opportunity to give a short presentation to the APS board before their convention started, in which I shared a bit of what we know about the barriers to expert participation in Wikipedia more broadly and then gave an overview of the Wikipedia Ambassador Program for helping professors run Wikipedia editing assignments in their classes. The reaction among board members was really encouraging… and that evening, Professor Banaji spent a few minutes at the beginning of the official opening of the convention exhorting APS members to get involved with Wikipedia. (She even mentioned me!)
Banaji’s enthusiasm for Wikipedia comes across clearly in a recent podcast about the APS Wikipedia Initiative. For the two main days of the convention, that enthusiasm seemed to carry over to the many psychologists who stopped by the lavish Wikipedia booth APS had set up. We also did five Wikipedia demos–often with conversations about Wikipedia going on at the same time with whoever stayed behind at the booth. I came back with a list of 42 instructors potentially interested in working with the ambassador program and doing Wikipedia assignments. That, of course, has been my focus for the last year… until now, limited mainly to supporting classes on public policy. Our Education Portal is active now, with a broad range of support materials and advice for anyone assigning Wikipedia to their students. (The sample syllabus, in particular, is something the psychology professors responded very positively to.)
It seems that Wikipedia in the classroom is where APS is converging now, too. The Wikipedia Initiative team will soon be working with an intern assigned to develop tools to help instructors evaluate their students’ contributions, which will hopefully produce something broadly useful for anyone running Wikipedia assignments.
I’m optimistic that we’ll see a wave of additional professional societies getting behind Wikipedia, especially if as many psychologists set their students on Wikipedia as I now expect. You can’t buy the kind of improvement in public representations of psychology that 50 classes of students editing Wikipedia would bring.
 A bit of superglue and a spare ring magnet makes it quite usable on my HTC One XL. Here are the same pixels from my television, shot with the microscope and with the macro lens. The fine structure of individual pixels resolves a little better with the microscope.
A bit of superglue and a spare ring magnet makes it quite usable on my HTC One XL. Here are the same pixels from my television, shot with the microscope and with the macro lens. The fine structure of individual pixels resolves a little better with the microscope.

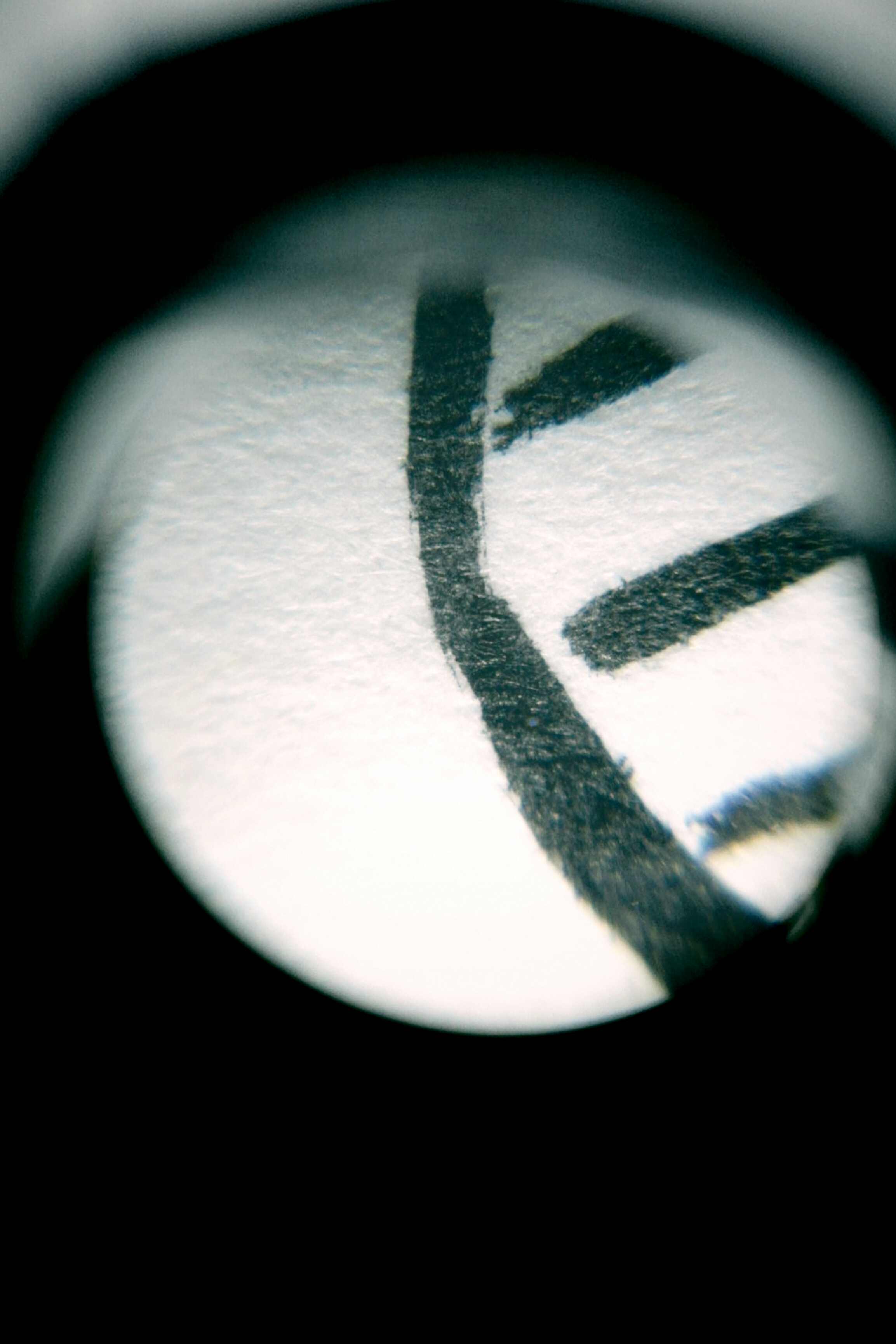 The main downside with this lens is that the visible area makes up only a small portion of the sensor. The shots above are “zoomed”; the visible area is actually about 1/3 the width of an uncropped image. Still, the design of the barrel along with the built-in lights makes it easier to get a good, well-lit image than it is with the macro (which creates disruptive shadows over the subject in most lighting). So, $5.23 well-spent.
The main downside with this lens is that the visible area makes up only a small portion of the sensor. The shots above are “zoomed”; the visible area is actually about 1/3 the width of an uncropped image. Still, the design of the barrel along with the built-in lights makes it easier to get a good, well-lit image than it is with the macro (which creates disruptive shadows over the subject in most lighting). So, $5.23 well-spent.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}